![]() Пред.
страница .
Пред.
страница .![]() След. страница
След. страница
![]() Раздел
Раздел ![]() Содержание
Содержание
2.1. Автоматные распознаватели
Грамматики типа три называются автоматными, потому что существует связь между этими грамматиками и конечными автоматами без выходов или распознавателями. Модель такого распознавателя состоит из входной ленты, читающей головки и устройства управления, как это показано на рис. 2.1.
При изучении формальных языков обычно предполагают, что слово, подаваемое на вход распознавателя, предварительно записывается на бесконечную входную ленту, ограниченную с одной стороны. Лента разделена на части, в каждой из которых может быть расположен один символ входного алфавита. Входное слово располагается всегда , начиная от левого края ленты. Предполагается также, что незаполненные ячейки, расположенные правее входного слова, содержат пустые символы, которые обозначаются греческой буквой ε
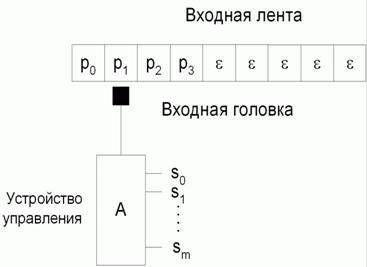
Рис. 2.1. Модель распознавателя
Чтение символов входного алфавита производится читающей головкой, которая после считывания символа сдвигается на одну позицию вправо. Прочитанный таким образом символ подаётся на вход устройства управления, которое может изменять свое состояние. Такой распознаватель (A)может быть определен совокупностью пяти компонентов:
А = { P, S, s0, φ, F},
где P - входной алфавит распознавателя,
содержащий символы, записываемые на входную ленту,
S - множество
состояний распознавателя,
s0 -
начальное состояние, которым является одно из состояний множества S,
φ - функция переходов,
задающая отображение
φ
: P×S → S
F - множество конечных состояний, которое
должно быть подмножеством S,
Эта функция каждой паре: состояние и входной символ ставит в
соответствие состояние распознавателя. В функциональной форме она записывается
так:
φ
(si, pk) = sm.
На практике
функцию переходов задают в виде двумерной таблицы, которую называют таблицей переходов распознавателя, или в виде
ориентированного графа, называемого диаграммой переходов распознавателя. При
построении таблицы переходов ее строки отмечаются состояниями распознавателя, а
столбцы обозначаются входными символами. В каждой клетке таблицы, которая
соответствует строке, отмеченной состоянием si, и столбцу, отмеченному входным символом pk, записывается состояние sm, определяемое функцией переходов φ (si, pk) = sm. Примером таблицы переходов распознавателя
является таблица 2.1. Состояния распознавателя в этой таблице обозначены
буквами латинского алфавита, а входной алфавит состоит из цифр 0 и 1.
Чтобы
построить диаграмму переходов распознавателя, нужно каждому состоянию сопоставить
вершину графа и пометить эту вершину символом состояния, а каждому переходу,
определяемому функцией φ
(si, pk) = sm, дугу графа sm, отмеченную входным символом pk и соединяющую вершины si, и sm . Диаграмма
переходов распознавателя, заданного табл. 2.1, изображена на рис. 2.1
Работа
распознавателя может быть представлена в виде последовательности тактов. Чтобы
описать работу распознавателя, введём понятие конфигурации. Конфигурация
распознавателя определяется состоянием si и ещё не прочитанной частью
входной цепочки α’ на ленте:
(si, α’).
В каждом такте происходит смена конфигурации распознавателя. Если такту
работы соответствует конфигурация (sk,pα'), где p- символ,
расположенный под читающей головкой, и, если определена функция переходов j(sk,p)=si, то
формируется новая конфигурация (si, α'), соответствующая
следующему такту работы.
Смену конфигураций обозначают специальным
символом и записывают так:
(sk,α) |-- (si, α').
Если существует последовательность
конфигураций, соответствующая последовательности
тактов работы распознавателя А
(si, α1) |-- (si2, α2) |-- ... |-- (sik, αk),
то её
обозначают следующим образом:
(si1, α1) |-- * (sik, αk)
Конфигурация, образованная начальным
состоянием s0 и ещё не прочитанной входной цепочкой α называется начальной конфигурацией и обозначается (s0,
α).
Конфигурация, образованная конечным состоянием из множества F и пустой цепочкой, называется конечной или заключительной конфигурацией.
Используя введённые термины, можно определить
два новых понятия.
Определение. Входное слово (цепочка) α называется допустимым для распознавателя А,
если при последовательном чтении символов α с входной ленты распознаватель переходит из
начальной конфигурации в одну из конечных конфигураций.
(s0, α) |-- *
(sk,$) и sk Î F
Определение. Множество цепочек L, допускаемых распознавателем А, назовём языком,
допускаемым этим распознавателем L(А).
L(А) = { α
| α Î P* и (s0, α) |-- * (sk,$) и sk
Î F}
В качестве иллюстрации рассмотрим работу распознавателя А1, который определятся множествами: P = {0, 1}, S = {A,
B, C, D},
F = {D}. Функция переходов этого распознавателя
задаётся таблицей 2.1.
Таблица 2.1. Таблица переходов
распознавателя А1
|
pk si |
0 |
1 |
|
A |
B |
A |
|
D |
C |
A |
|
C |
D |
C |
|
D |
- |
- |
Этой таблице
соответствует диаграмма переходов, изображенная на рис. 2.2
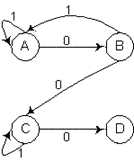
Рис. 2.2. Диаграмма переходов распознавателя А1.
Работа
распознавателя для входной цепочки 01001
может быть представлена в виде последовательности конфигураций
(A,01001) |-- (B,1001) |-- (A,001) |-- (B,01) |-- (C,1) |-- (C,$),
которая показывает, что цепочка не допускается распознавателем А1, поскольку он не достигает конечного состояния после прочтения всех входных символов.
Введенные понятия позволяют определить связь между формальными грамматиками и распознавателями путем установления соответствия языков, порождаемых грамматиками, и языков, допускаемых распознавателями.
Для
автоматных грамматик и распознавателей соответствие этих понятий определяется
следующим утверждением.
Утверждение 2.1. Для каждого распознавателя существует
А-грамматика, порождающая язык, совпадающий с множеством цепочек, допускаемых
распознавателем.
Чтобы показать справедливость этого утверждения, рассмотрим построение
грамматики по заданной диаграмме переходов распознавателя. Такое построение
заключается в следующем. Для каждой пары состояний распознавателя X и Y ,
соединённых дугой, исходящей из X , заходящей в Y и помеченной входным символом
p, построим правило грамматики вида <X> → a <Y>, если
состояние Y не является конечным состоянием распознавателя, или - правило
<X> → a, если Y - конечное состояние.
Полученное таким образом множество правил определяет грамматику,
которая порождает язык, допускаемый заданным распознавателем. Действительно,
каждая порождаемая распознавателем цепочка a
будет вызывать последовательность переходов распознавателя, а каждому переходу
соответствует правило грамматики, поэтому последовательность переходов при
чтении символов цепочки a будет
соответствовать последовательности применения правил грамматики, то есть выводу
этой цепочки в построенной грамматике. Применим описанный способ построения к
распознавателю А1. В результате получим грамматику со схемой:
R= <A> →
1 <A>,<A> → 0 <B>, <B> → 1 <A>,
<B> → 0 <C>,
<C> → 1 <C>, <C> → 0
Рассмотрим ещё один пример построения
грамматики для распознавателя А2, который задан диаграммой
переходов, изображенной на рис 2.3.
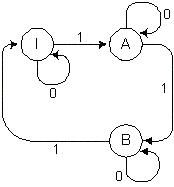
Рис 2.3. Диаграмма переходов распознавателя А2
Этот распознаватель имеет одно конечное состояния, которое совпадает с его начальным состоянием F= {I}.
Это обстоятельство следует учесть при построении правила грамматики,
соответствующего переходу из состояния B в состояние I.
Сама грамматика, построенная по диаграмме распознавателя А2,
имеет вид:
R=
<I> ® 0 <I>
<I> ® 1 <A>
<A> ® 0 <A>
<A> ® 1 <B>
<B> ® 0 <B>
<B> ® 1 <I>
Второе
утверждение, показывающее связь автоматных грамматик и распознавателей,
формулируется следующим образом.
Утверждение2.2. Для каждой А-грамматики, которая порождает
язык, не содержащей пустой цепочки, существует распознаватель, множество
допустимых цепочек которого совпадает с языком, порождаемым заданной
грамматикой.
Чтобы показать оправданность этого
утверждения, вначале опишем способ построения распознавателя по заданной
грамматике.
Построение предусматривает выполнение двух
этапов: вначале осуществляется преобразование заданной грамматики, а затем
построение диаграммы переходов распознавателя.
Преобразование заданной грамматики
выполняется следующим образом.
Дополним алфавит VА ещё одним
символом <Z>.Все заключительные правила грамматики вида <A> ® a преобразуем в правила вида <A> ®a <Z>. Добавим правило <Z> ® $. Остальные правила оставим без изменения.
Построение диаграммы переходов распознавателя
выполняется по следующим правилам:
1) поставим в соответствие каждому
нетерминальному символу узел графа,
2) для каждого правила <A> ® a
<B> соединим дугой узлы A и B и отметим эту дугу символом a,
3) узел, отмеченный начальным символом
грамматики, примем в качестве начального узла, а узлы, отмеченные символом
<Z> , в качестве конечных узлов графа (узлы, для которых имеются правила
Z ® $ , считаем заключительными).
В результате построения получаем
распознаватель, допускающий язык, порождаемый заданной грамматикой, поскольку
каждому выводу цепочки a в заданной
грамматике соответствует последовательность переходов в построенной диаграмме
переходов распознавателя.
В качестве примера построим распознаватель
для грамматики Г2.1
Г2.1: R= {<I> ® a <I>, <I> ® a <A>,
<A> ® b <A>,
<A> ® b}
После
преобразования получаем грамматику Г2.1'
и диаграмму переходов искомого распознавателя в виде:
Г2.1': R=
{<I> ® a <I>, <I> ® a <B>, <B> ® b <B>,
<B> ® b <Z>, <Z> ® $}
Диаграмма распознавателя A3, построенного по
этой грамматике, изображена на рис. 2.4.
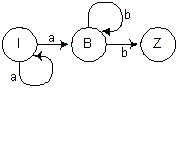
рис. 2.4. Диаграмма переходов распознавателя A3, построенного для правосторонней грамматики Г2.1'
В приведённых выше утверждениях и примерах рассматривались
правосторонние грамматики, поскольку они обеспечивают построение цепочек языка
в порядке слева направо так, как принято строить выражения в языках
программирования. В отличии от правосторонних левосторонние грамматики стоят
цепочки языка в порядке справа налево. Однако, для каждой правосторонней
грамматики можно построить эквивалентную ей левостороннюю грамматику.
Такое построение проще всего осуществить путем преобразования диаграммы
переходов распознавателя, построенного для заданной правосторонней грамматики.
Преобразование можно выполнить следующим образом:
a) обозначения начальной и конечной вершин на
диаграмме переходов надо поменять местами,
b) поменять направление всех дуг на диаграмме
переходов на противоположное.
Если выполнить описанные преобразования для диаграммы переходов
распознавателя А3, построенного по правосторонней грамматике Г2.1',
то получим диаграмму распознавателя А4, приведенную на рис. 2.5.
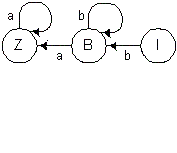
Рис. 2.5. Диаграмма переходов распознавателя A4, соответствующего левосторонней грамматике.
Этой диаграмме соответствует левосторонняя грамматика, схема которой
имеет вид:
R = {<I> →
<B> b, <B> → <B> b, <B> → <Z> a,
<Z> → <Z> a }.
![]() Пред.
страница .
Пред.
страница .![]() След. страница
След. страница
![]() Раздел
Раздел ![]() Содержание
Содержание