![]() Пред.Страница
Пред.Страница ![]() След.Страница
След.Страница ![]() Раздел
Раздел![]() Содержание
Содержание
6.4. Распознавание лексем
Выявление лексем во входном тексте может быть выполнено с помощью распознавателя. Обычно лексемы определяются с помощью автоматных грамматик, поэтому распознаватель лексем должен представлять собой конечный автомат. Для построения распознавателя необходимо иметь грамматику, порождающую последовательность лексем заданного входного языка, наборы символов, определяющие начало и конец каждой лексемы. Эти данные могут быть получены из заданной схемы грамматики. Так схема грамматики для последовательности лексем может быть построена на основе определений лексем. Наборы символов для начала и конца лексемы, обозначенной соответственно нетерминальными символами L и K, определяются функциями ПЕРВ(L) и СЛЕД(K).
Порядок построения схемы грамматики для последовательности лексем может быть описан следующим образом:
- В заданной грамматике входного языка выделить правила, определяющие лексемы L1, L2, … , Lr.
- Каждое правило, определяющее лексему Lj, вида Lj ®x Aj заменить правилом I®x Aj, где I – начальный символ искомой грамматики.
- Для каждой лексемы имеющей заключительное правило Lj ®x заменить это правило правилом вида Lj ®xZ, где Z – конечный символ искомой грамматики.
- Для
каждой лексемы имеющей заключительное правило Kj
®$,
построить множество СЛЕД(Kj)
= { xj1,
xj2,
…, xjq } и множество правил вида:
Kj ® xj1Z | xj2 Z |…| xjqZ. - Для
каждой лексемы Lj,
состоящей из нескольких символов с1, с2,…, сm
построить цепочку правил вида:
Lj ® с1B1 | с2 B2 |…| сm Z. - Если
в грамматика имеется две многосимвольные лексемы Lj
и Lk, такие что символы Lk представляют собой начальный отрезок лексемы Lj, например,
Lk®с1,
то нужно построить множество СЛЕД(с1) = { zj1,
zj2,
…, zjt }, исключить из этого множества символ с2 и
построить множество правил вида:
B1® zj1Z | zj2 Z |…| zjtZ. - Объединить начальное состояние I и заключительное состояние Z, чтобы построить распознаватель многократного действия.
В результате выполнения перечисленных действий получим автоматную грамматику, порождающую заданную последовательность лексем. Затем по этой грамматике построим распознаватель лексем заданного входного языка.
В качестве примера рассмотрим построение грамматики последовательности лексем для входного языка, приведенного в предыдущем разделе.
Лексемами этого языка являются, во-первых, идентификаторы и числа, которые описываются следующими правилами:
<Идентификатор>
::= <буква><Про_идентификатор>
<Про_идентификатор>::=
<буква><Про_идентификатор> |
<цифра><Про_идентификатор>
<Про_идентификатор>::=
$
<Число>
::= <цифра><Про_число>
<Про_число>::=
<цифра><Про_число>
<Про_число>::=
$
<буква>::=a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
<цифра>
::= 0|1|2|3|4|5|6|7|8|9
Множества символов, которые могут следовать за этими лексемами, определяются следующими функциями:
СЛЕД(<Про_идентификатор>) = {:,;, =, &, |, !, ), ,},
СЛЕД(<Про_число>) = {;,&, |, )}.
Добавим к описанию лексем правила, завершающие лексемы, начальный и конечный символы грамматики, а также обозначим нетерминальные символы буквами A и B.
В результате поучаем правила искомой грамматики в виде:
<I> ::= <буква><A>
<A>::= <буква><A> | <цифра><A>
<A>::= :Z | ;Z | =Z |
&Z | ‘|’Z | !Z | )Z | ,Z
<I> ::= <цифра><B>
<B>::= <цифра><B>
<B>::= ;Z | &Z | ‘|’Z | )Z
<буква>::=a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
<цифра>::=
0|1|2|3|4|5|6|7|8|9
Во-вторых, лексемами являются знаки отношения, состоящие из двух символов. При построении правил для этих лексем необходимо учесть, что первый символ знака равенства совпадает с символом, обозначающим оператор присваивания.
Порождающие правила для этих лексем запишем так:
<Отношение>
::= !<Про_неравенство>
<Про_неравенство>::=
=<Про_отношение>
<Совпадающие_знаки>
::= =<Про_совпадающие_знаки>
<Про_совпадающие_знаки>::= $
<Про_совпадающие_знаки>::= = <Про_отношение>
<Про_отношение>::=
$
Заменяя нетерминальные символы буквами C, D, E и учитывая символы, завершающие лексемы,
СЛЕД(=) = { (, ~, <буква>},
СЛЕД(==) = { <буква>, <цифра> },
получаем правила искомой грамматики в виде:
<I> ::= !<C>
<C> ::= =<E>
<I> ::= =<D>
<D>::= (Z | ~Z | <буква>Z
<D>::= = <E>
<E>::= <буква>Z| <цифра>Z .
В-третьих, лексемами являются односимвольные терминалы, являющиеся разделителями и знаками операций. Для таких лексем построим правила вида:
<I>::= (Z | )Z
| ;Z | &Z | VZ
| ~Z |<Z |>Z |,Z|
:Z.
Множество построенных порождающих правил является схемой грамматики, порождающей последовательность лексем заданного входного языка. Этим правилам соответствует представленная на рисунке 6.4 диаграмма переходов автомата, являющегося распознавателем лексем.
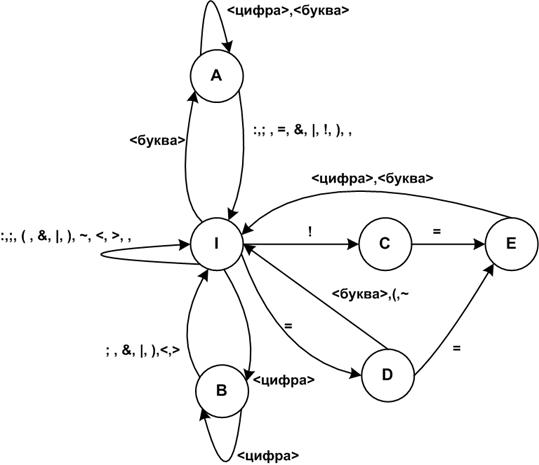
Рис. 6.4. Диаграмма переходов распознавателя лексем
![]() Пред.Страница
Пред.Страница
![]() След.Страница
След.Страница ![]() Раздел
Раздел![]() Содержание
Содержание