![]() Пред.Страница
Пред.Страница ![]() След.Страница
След.Страница ![]() Раздел
Раздел![]() Содержание
Содержание
6.5. Трансляция лексем
Процесс трансляции лексем можно описать с помощью схемы трансляции, представляющей собой транслирующую грамматику, у которой выходные символы заменены программными фрагментами, называемыми семантическими действиями. Такие фрагменты, также как выходные символы, указываются в правой части правил грамматики с помощью фигурных скобок. В свою очередь, схема трансляции является основой для построения преобразователя, осуществляющего трансляцию. Семантические действия могут потребовать описания вспомогательных функций и процедур, обусловленных программной реализацией процесса трансляции. Так, процесс трансляции лексем предполагает пошаговое выделение символов входного текста и их распознавание. Следовательно, необходимо сохранять начальные части многосимвольных лексем до обнаружения заключительного символа. Обычно для этой цели используется символьная переменная buffer и переменная целого типа buf_count для подсчета числа символов, записанных в буфер. Для работы с буфером определим следующие процедуры, учитывающие особенности построенного распознавателя:
· {start_buf} – процедура, выполняет очистку буфера и сброс счетчика. Она должна вызываться перед обработкой первого символа каждой лексемы.
· {add_buf} - процедура, выполняет запись текущего входного символа в буфер и увеличивающая значение счетчика. Она должна вызываться для каждого входного символа. Если во входном языке предусмотрены ограничения на длину идентификаторов или чисел, то контроль длины может выполняться этой процедурой.
· {еnd_num} - процедура, выполняет поиск числа, находящегося в буфере, в таблице символов (или в таблице чисел) и запись этого числа в таблицу, если оно там отсутствует. Кроме того, процедура должна построить соответствующий токен и записать его в выходной массив. Она должна вызываться при обнаружении символа, указывающего конец числа.
· {еnd_idn} - процедура, выполняет поиск идентификатора, находящегося в буфере, в таблице символов и запись этого идентификатора в таблицу, если оно там отсутствует. Если идентификатор уже записан в таблицу символов и совпадает с одним из символов, расположенных в начале таблицы, то процедура должна классифицировать его как служебное слово. Кроме того, процедура должна построить соответствующий токен и записать его в выходной массив. Она должна вызываться при обнаружении символа, указывающего конец идентификатора.
· {еnd_lim1} - процедура, выполняет построение токена для односимвольного разделителя, находящегося в буфере, и запись его в выходной массив. Она должна вызываться при обнаружении односимвольного разделителя.
· {еnd_lim2} - процедура, выполняет построение токена для двухсимвольного разделителя, находящегося в буфере, и запись его в выходной массив. Она должна вызываться при обнаружении символа, указывающего конец двухсимвольного разделителя.
После включения приведенных выше процедур во входную грамматику, описывающую последовательность лексем, получаем схему транслирующей грамматики, задающей перевод лексем, в следующем виде:
<I> ::= <буква>{start_buf}{add_buf}<A>
<A>::=
<буква>{add_buf}<A>
| <цифра>{add_buf}<A>
<A>::= ;{end_idn}I | ={end_idn}I | &{end_idn}I |
V{end_idn}I| ){end_idn}I | ,{end_idn}I | !{end_idn}I
<I>::= ;{end_lim1}I | ~{end_lim1}I | &{end_lim1}I |
‘|’{end_lim1}I| ){end_lim1}I | ,{end_lim1}I| ){end_lim1}I|
<{end_lim1}I
| >{end_lim1}I
<I> ::= <цифра>{start_buf}{add_buf} <B>
<B>::=
<цифра>{add_buf}
<B>
<B>::=
;{end_num}I | &{end_num}I | V{end_num}I | ){end_num}I
<буква>::=a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
<цифра>::=
0|1|2|3|4|5|6|7|8|9
<I> ::= !{start_buf}{add_buf}<C>
<C> ::= ={add_buf}<E>
<I> ::= ={start_buf}{add_buf}<D>
<D>::= ({end_lim1}I | ~{end_lim1}I | <буква>{end_lim1}I
<D>::= = {add_buf}<E>
<E>::= <буква>{end_lim2}I| <цифра>{end_lim2}I .
<I> ::=
#<F>
<F>::=<цифра><F>|
<буква>F>
<F> ::= #I
Построенной транслирующей грамматике соответствует конечный преобразователь, диаграмма переходов которого приведена на рисунке 6.5. На диаграмме косая черта отделяет последовательность входных символов, вызывающих смену состояния, от последовательности выходных символов. Этот преобразователь перерабатывает последовательности символов, представляющих программу на входном языке, в последовательность лексем.
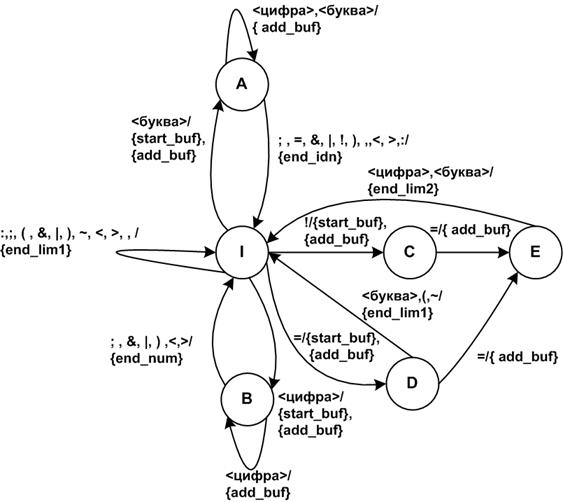
Рис. 6.5. Диаграмма переходов преобразователя, реализующего перевод лексем.
В случае программной реализации лексического анализатора, обычно в памяти компьютера хранят не диаграмму переходов преобразователя, а таблицу переходов.
Таблица 6.2. Таблица переходов и выходов лексического преобразователя
|
|
A |
B |
C |
D |
E |
I |
|
<буква> |
A {add_buf} |
|
|
I {end_lim2} |
I {end_lim2} |
A {start_buf} {add_buf} |
|
<цифра> |
A {add_buf} |
B {add_buf} |
|
|
I {end_lim2} |
B {start_buf} {add_buf} |
|
; |
I {end_idn} |
I {end_num} |
|
|
|
I {end_lim1} |
|
& |
I {end_idn} |
I {end_num} |
|
|
|
I {end_lim1} |
|
| |
I {end_idn} |
I {end_num} |
|
|
|
I {end_lim1} |
|
) |
I {end_idn} |
I {end_num} |
|
|
|
I {end_lim1} |
|
, |
I {end_idn} |
|
|
|
|
|
|
( |
|
|
|
I {end_lim2} |
|
I {end_lim1} |
|
~ |
|
|
|
I {end_lim2} |
|
I {end_lim1} |
|
! |
I {end_idn} |
|
|
|
|
C {start_buf} {add_buf} |
|
= |
I {end_idn} |
|
E {add_buf} |
E {add_buf} |
|
D {start_buf} {add_buf} |
|
< |
|
|
|
|
|
I {end_lim1} |
|
> |
|
|
|
|
|
I {end_lim1} |
|
: |
|
|
|
|
|
I {end_lim1} |
Таблица переходов преобразователя является основой для написания программы, реализующей его работу. При этом в зависимости от способа представления такой таблицы в памяти компьютера могут быть построены различные программы.
![]() Пред.Страница
Пред.Страница ![]() След.Страница
След.Страница ![]() Раздел
Раздел![]() Содержание
Содержание